The Best Databases for Embedded Analytics in 2026
If you want your analytics experience to load in real-time, you need a database that supports low latency and high concurrency–among other features. In this article, we explore the differences between Rockset, ClickHouse, Apache Druid, and Apache Pinot for you to choose the best one for your needs.
Summarize with:
When it comes to user-facing analytics, you need a database that supports sub-second query responses, near real-time updates, and high QPS (concurrent Queries-per-second).
In other words, while you may be able to wait a couple of minutes for results to come back for your business intelligence (BI) report to share with internal stakeholders, your end users don’t want to wait more than a few seconds to see results and take action in your platform. Hence, you need a data stack to keep up with the required pace.
We’ve analyzed the four best-regarded real-time analytics databases to help you answer the question: What’s the best database for customer-facing analytics? Spoiler alert: It depends on your needs, but we can help you make the call.
Let’s see what ClickHouse, Apache Druid, and Apache Pinot have to offer.
Considering a Headless BI architecture? Find out what headless BI is and how it could benefit your business here.
What is customer-facing analytics? (+ how it’s different from internal BI)
Customer-facing analytics is when you present data to your end-users so they can gain insights from it and take action. It can increase your product's real and perceived value by presenting business metrics in a digestible and immediate way.
For example, real-time user-facing analytics is critical for things like live trading applications, health monitoring tools, or even delivery apps that show precisely how many minutes it’ll take to get your food.
Data warehouses optimized for internal BI vs real-time databases for user-facing analytics
Internal BI, on the other hand, is all about presenting business information to data analysts or managers for company use. So, in the delivery app example, internal BI would show metrics like the number of daily users, best-performing restaurants, and average delivery time so the team can perform data analysis and get relevant insights.
“There’s a big difference between database types,” says Tom Gardiner, CEO at Embeddable. “Their individual qualities should be carefully considered when planning for different applications—to ensure you can deliver the desired result.”
Internal BI tools typically use data warehouses to store and process large volumes of historical data. They usually process data in batches rather than in real time. It’ll have a completely different performance compared to the kind of database you need to build customer-facing analytics (which we’ll discuss later).
Three key differentiating factors between databases for BI and real-time analytics are:
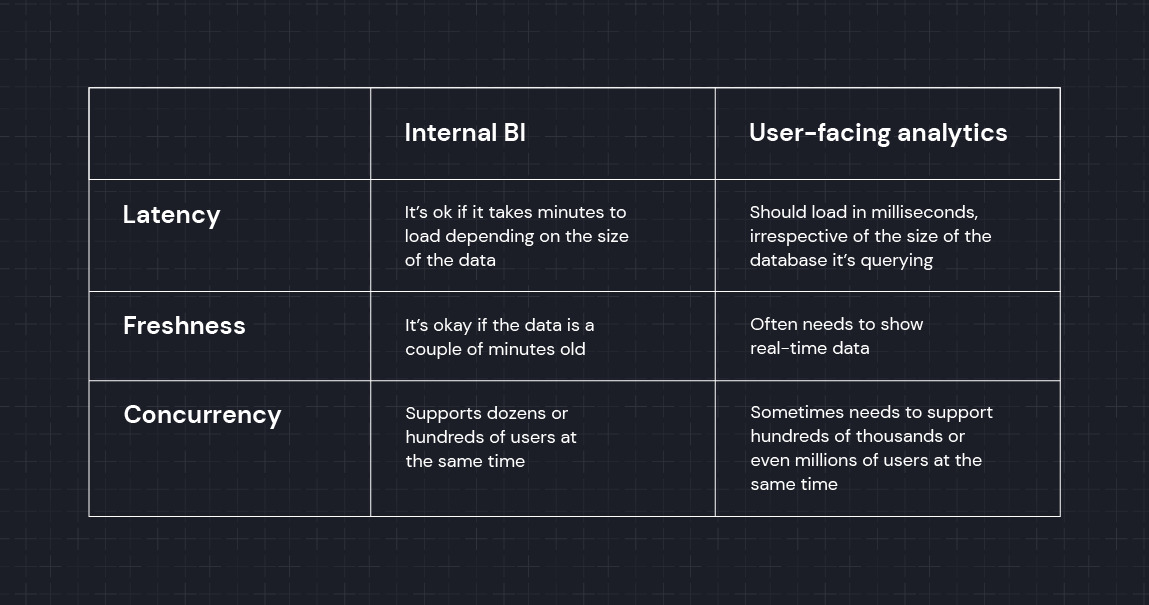
- Examples of BI data warehouses include Redshift, Snowflake, and Google BigQuery
- Examples of real-time databases for analytics include Rockset, ClickHouse, Cassandra, Apache Druid, and Apache Pinot.
👉 Learn when to use headless BI.
What to look for in a database for real-time analytics
In short, a good database for real-time analytics needs to process data efficiently, scale, load fast, and connect to your tech stack. Here’s each characteristic in more detail:
High-performing and cost-effective
Databases for user-facing analytics need to manage, structure, process, and store data at an affordable price—taking scalability into account. That’s because the solution needs to cater to the demands of a customer, delivering responses fast to large numbers of users and handling peaks and troughs of activity from those data consumers.
The best way to achieve this is by using a database that organizes the data efficiently (so the queries can run fast). It should also be able to process large datasets at a fair price, keeping your overheads manageable as it stores data.
Real-time loading
Real-time loading is critical because it ensures a smoother, more efficient user experience and allows people to make decisions faster and based on accurate data.
“When it comes to customer-facing analytics, the customers we speak to almost invariably want it to load fast,” says Tom. So, look for databases with high query per second (QPS), data freshness, and sub-second query responses. Optimizing for constant batch processing or data streaming will give users access to the most updated data version at all times.
Integrations
You also need to ensure your data management provider is compatible with your tech stack. You want it to connect to your data sources, embedded analytics solution, and other analytics tooling you might use.
If you’re using Embeddable, the toolkit for creating fast, fully bespoke user-facing analytics experiences, it integrates with Clickhouse and Druid. Embeddable will be able to connect with Rockset and Pinot as of Q1 2024.
Types of database management systems
Before discussing the best databases for analytics, let's first discuss database management systems, the software that helps organize, access, and manage the data.
1. Relational database management system (RDBMS)
A relational database management system is based on a structured schema with tables consisting of rows and columns, and it uses Structured Query Language (SQL) for querying and managing data. It ensures data integrity and ACID (Atomicity, Consistency, Isolation, Durability) compliance.
Examples: MySQL, PostgreSQL, Oracle Database, Microsoft SQL Server.
2. NoSQL database management system
This system type is designed for handling unstructured, semi-structured, or distributed data and doesn't rely on a fixed schema.
Four common types of NoSQL databases:
- Key-value stores: Data stored as key-value pairs (e.g., Redis, DynamoDB).
- Document stores: JSON-like documents (e.g., MongoDB, CouchDB).
- Column-family stores: Stores data in columns instead of rows (e.g., Apache Cassandra, HBase).
- Graph databases: Uses nodes and edges for complex relationships (e.g., Neo4j, ArangoDB).
3. Object-oriented database management system (OODBMS)
This system stores data as objects, similar to object-oriented programming. It is particularly useful for applications requiring complex data relationships.
Examples: ObjectDB, db4o, Versant.
4. Hierarchical database management system
In this system, the data is structured in a tree-like hierarchy, and each parent node can have multiple child nodes, but each child has only one parent in the structured data system.
Examples: IBM Information Management System (IMS).
5. Network database management system
This system is similar to hierarchical databases but allows multiple parent-child relationships (many-to-many). It uses a graph structure for flexible relationships.
Examples: IDMS (Integrated Database Management System), CA-Datacom.
6. Time-series database (TSDB)
This system is optimized for handling time-stamped data such as logs, IoT, and financial data.
Examples: InfluxDB, TimescaleDB, OpenTSDB.
7. Columnar database management system
This system stores data in columns instead of rows for faster analytical queries. Due to this columnar storage, it is often used in data warehouses and big data applications.
Examples: Amazon Redshift, Apache HBase, Google BigQuery.
8. NewSQL database management system
This hybrid approach combines the scalability of NoSQL with the ACID compliance of SQL databases.
Examples: CockroachDB, Google Spanner, MemSQL.
9. In-memory database management system
This system stores data in RAM for high-speed access, and it's suitable for real-time applications.
Examples: SAP HANA, Redis, VoltDB.
10. Distributed database management system (DDBMS)
This system distributes the data across multiple locations (cloud, clusters). It ensures high availability and fault tolerance.
Examples: Google Spanner, Amazon Aurora, Apache Cassandra.
4 best real-time analytics databases
Choosing the correct database for storing and querying data can be very impactful. This can ultimately affect your app’s performance and customer experience.
To help you out, we’ve compared our four favorite real-time analytics databases. Rockset, ClickHouse, Apache Druid, and Apache Pinot can all:
- Process online analytical processing (OLAP) style queries
- Handle high queries per second (QPS) and are incredibly fast
- Support customer-facing analytics
- Perform much faster than data warehouses like BigQuery, Snowflake, and Redshift (but might be less cost-efficient)
Let’s take a look at each one in depth.
1. ClickHouse: Best database with batch ingestion
![]()
ClickHouse ingests data from different types of databases and it’s compatible with multiple programming languages and data visualization tools. Source: ClickHouse
ClickHouse is an open-source database. It is column-oriented, distributed, and OLAP, so it's very easy to set up and maintain. “Because it’s columnar, it’s the best architectural approach for aggregations and ‘sort by’ on multiple columns. It also means that group by’s are very fast. It’s distributed, replication is asynchronous, and it’s OLAP—which means it’s meant for analytics,” says Tyler Hannan, Senior Director of Developer Advocacy at ClickHouse.
Things to consider about ClickHouse
ClickHouse allows you to query and perform several million writes per millisecond (check for yourself here), making this a very efficient database. Users choose ClickHouse for:
- Real-time dashboards
- Real-time analytics
- Business intelligence (BI)
- Data warehouse speed layer
- Logging and metrics
- Machine learning (ML) and data science
This database provider uses materialized views for performance. This means you must know how your query patterns will look upfront to get the best performance. Once you do, ClickHouse becomes a good alternative to data warehouses. “You need to define the relevant materialized views beforehand, but then, you get fantastic performance on those queries,” says Tom.
ClickHouse also optimizes ingest throughput by batching data ingestion. This makes it great for ingesting high data volumes, but it doesn’t guarantee that the latest inserted data will be part of a query result. This is because it needs to recreate materialized views in each batch update.
Companies that use ClickHouse
These are some of the companies using ClickHouse for real-time dashboards and analytics:
- Cloudflare
- Microsoft
- Contentsquare
- OpenSea
- highlight.io
- Dassana
- Disney+
- GraphQL
- Plausible
What we think of ClickHouse
If you want to use a database with a fast speed batch ingestion instead of streaming data, ClickHouse might be the right option. This super-fast database and its columnar approach make it great for aggregations in real-time analytics.
ClickHouse is also very efficient; it runs fast on your CPU or the cloud and uses your system resources well. However, it doesn’t support full-fledged transactions. It won’t let you edit or delete already inserted data with a high rate and low latency (you can do this in batches).
2. Apache Druid: Best database for enterprises
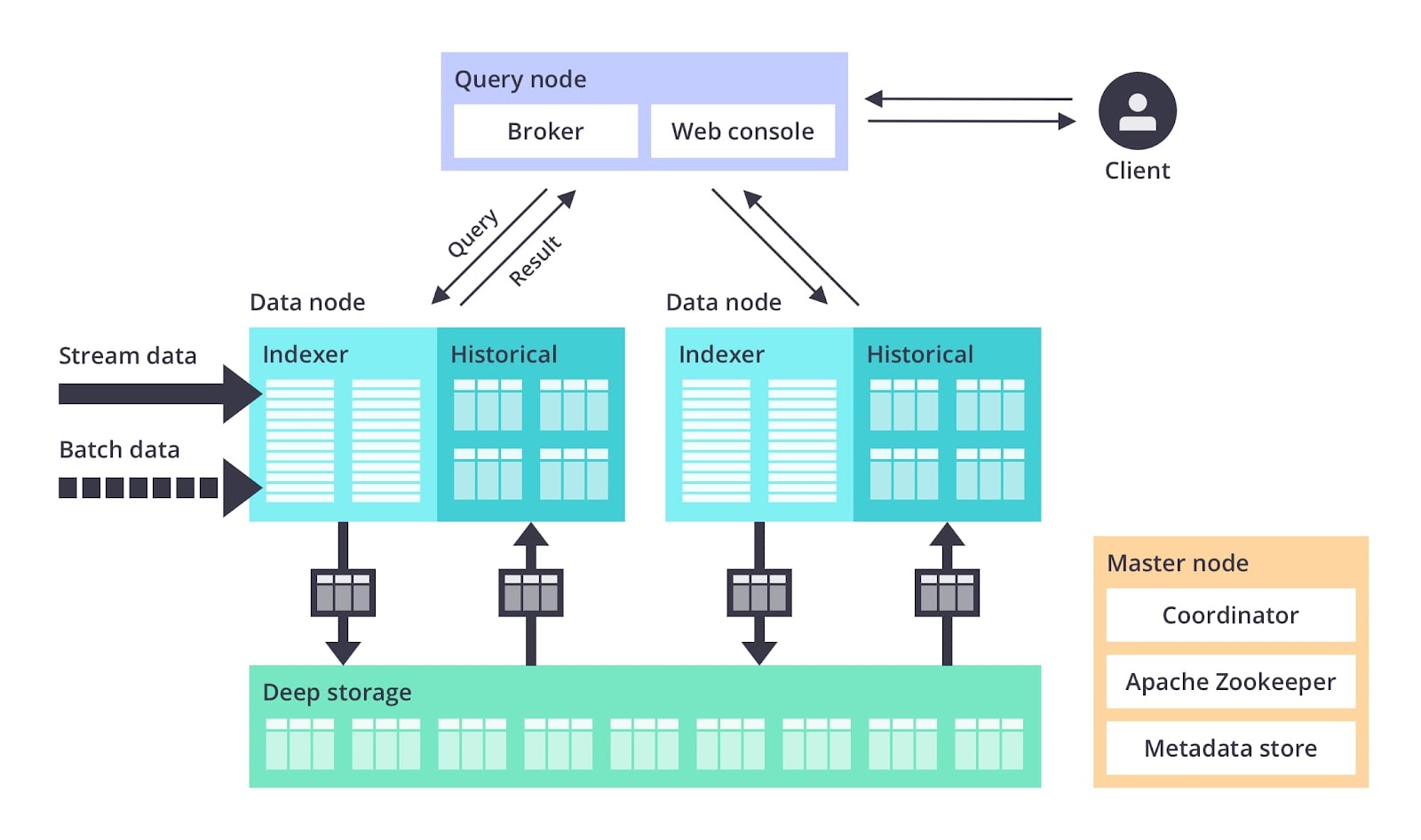
Every time a customer makes a query, Druid looks into its data nodes that are properly indexed and gives them an answer in milliseconds. Source: Apache Druid
Apache Druid is a fast and efficient database for real-time analytics applications. It’s high-performing, thanks to its low query latency, even while handling multi-tenancy. Druid can run sub-second queries at a large scale.
Things to consider about Apache Druid
Druid makes analytics available in real time because it supports stream-based ingestion using Apache Kafka and Amazon Kinesis APIs. Since it also allows batching ingestion from multiple servers, sources and formats, it can access historical data in milliseconds. “It makes the latest ingested data available immediately, which is great for data freshness,” says Tom.
This database specializes in ranking, groupby, counting, and time trends. Since Druid is designed for big enterprises, it can handle vast amounts of data and scales very well, but also requires a dedicated team.
Apache Druid also has many enterprise features, such as allowing you to prioritize particular queries, like jumping important jobs ahead of the queue. Users also like it because it supports high concurrency, which is particularly useful for real-time analytics and uses where accurate business metrics are crucial. It's also a great skill to highlight on a data analyst CV.
“When you're dealing with highly concurrent environments, you need an architecture that’s designed for that CPU efficiency to get the most performance out of the smallest hardware footprint—which is another reason why folks like to use Apache Druid,” says David Wang, VP of Product and Corporate Marketing at Imply. (Imply offers Druid as a service.)
Companies that use Apache Druid
These are some of the brands that use Druid for real-time analytics:
- Airbnb
- Alibaba
- Cisco
- Deep.BI
- GumGum
- Nielsen
- Salesforce
- Shopify
- Verizon
What we think of Apache Druid
Druid is an excellent option for businesses with large user bases as it was built for multi-tenancy, and it’s super fast at high concurrency. It may be the fastest analytical database for complex analytics.
What we like the most about Druid is that it lets you prioritize queries. However, some say this is a feature you wouldn’t need to use with something like ClickHouse as that aims to make all queries very fast loading (so in theory, there’s no reason to prioritize one over the other).
The downside to Apache Druid is that it requires a lot of dev time to operate. So, while saving money on the system, you might need to hire or spend more developer hours just to manage the database.
3. Apache Pinot: Best for indexing data
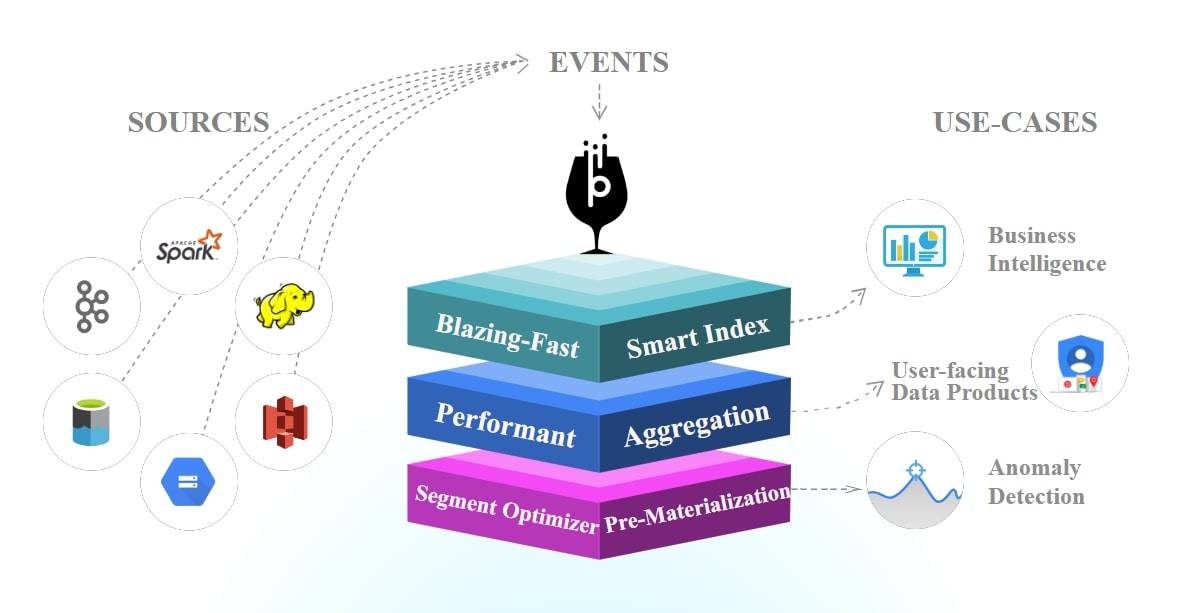
Connect your SQL or NoSQL databases, data lakes, and preferred sources to Apache Pinot and query all data types to gain fast responses. Source: Apache Pinot
Apache Pinot is a tabular, distributed, OLAP datastore for big data real-time analytics. It was built by the LinkedIn engineering team after they outgrew Apache Druid.
Things to consider about Apache Pinot
It ingests data from operational data, data warehouses, data lakes, and data streams.
The biggest value behind Apache Pinot is that you can index each column, which allows it to process data at a super-fast speed.
“It’s like taking a pivot table and saving it to disk. So you can get this highly dimensional data with pre-computed aggregations and pull those out in what seems like supernaturally fast time,” says Tim Berglund, Developer Relations at StarTree. (StarTree.ai offers Pinot as a service.)
So, Apache Pinot is great for enterprises with millions of end-users because it provides fast answers to concurrent queries. Just like Druid, it supports stream and batch ingest, and you can combine the two data models.
Companies that use Apache Pinot for analyzing data
In the list of businesses that use Apache Pinot, you’ll find:
- Zoho
- Uber
- Microsoft Teams
- 7-Eleven
- Hyundai
- Walmart
- Target
- NVIDIA
What we think of Apache Pinot
Apache Pinot is best for massive companies with a huge user base (think LinkedIn, Instagram, or TikTok). We really like its indexing and tiered storage because it makes complex analytical queries run very fast.
Pinot also offers smart data layouts that improve database performance. The main issue users report with Pinot is that it has limited support for joins and prefers inserts to updates, but the tradeoff is that you can get incredible performance at scale.
4. Rockset: Best for if you're Open AI*
*IMPORTANT NOTE: As of June 2024, Rockset has been acquired by OpenAI and will be off-boarding all customers from their services, so you'll have to look into other databases. Here's a look of what you could have had...
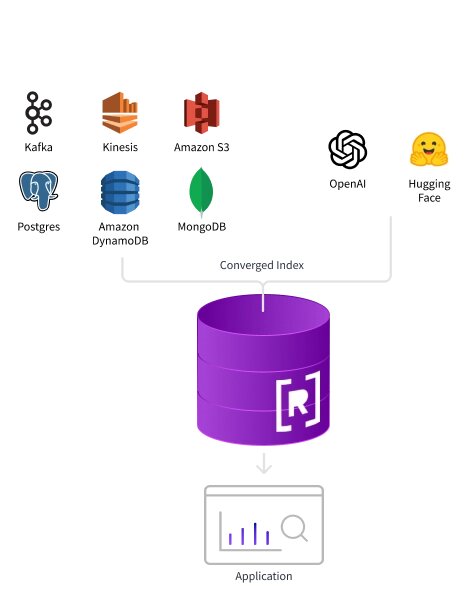
Bring your data to Rockset and connect it to your application for end users to ask questions and get fast responses. Source: Rockset
Rockset is a cloud-based real-time analytics database. It’s also fully managed, which means the company handles the effort of running it and takes it off your hands.
Things to consider about Rockset
Ingestion in Rockset works just like the tools mentioned, as you can insert data from streams, lakes, or operational databases by batching or streaming. However, the most significant benefit of Rockset is that it’s optimized for ingest latency. “This means it’s good for reliable freshness as the newly ingested data is immediately available for querying,” says Tom.
You can query data directly from Rockset’s database engine using a simple SQL (structured query language) script to turn into an API key and add to the application. It’s easy to use and has the best join support of all the competitors. A couple of features that will help reduce effort from your engineers include:
- It infers your database schema from the data on ingest (no need to specify schema upfront)
- Supports unstructured data like JSON
- Data is indexed automatically, so you don't need to determine query patterns upfront
- It automates configuration, deployment, and data redundancy
According to Rockset, it’s the fastest real-time analytics dashboard with 90MB/s Streaming Ingest. 70ms p95 Query Latency; 20,000 QPS. This makes it suitable for a variety of data analytics use cases.
Companies that (used to*) use Rockset
Many brands choose Rocketset as their real-time analytics database. These include:
- JetBlue
- WindWard
- Allianz
- Meta
- Sequoia
- SkyHive
- Seesaw
- Clinical ink
- Command Alkon
What we think of Rockset
We like how fast Rockset is and how easy it’s on your (/Open AI's*) engineering team to use this solution. However, it’s one of the newer solutions, so it doesn't yet have the same ecosystem or community as some other players.
Something else to consider: Some users report that it’s designed for up to 10s of terabytes of data, so you'll need to prioritize what data to ingest (unlike a data warehouse, where you can ingest everything and worry about how to use it later). But maybe it makes sense to think about what data matters!
Make a decision: Which database is right for your analytics needs?
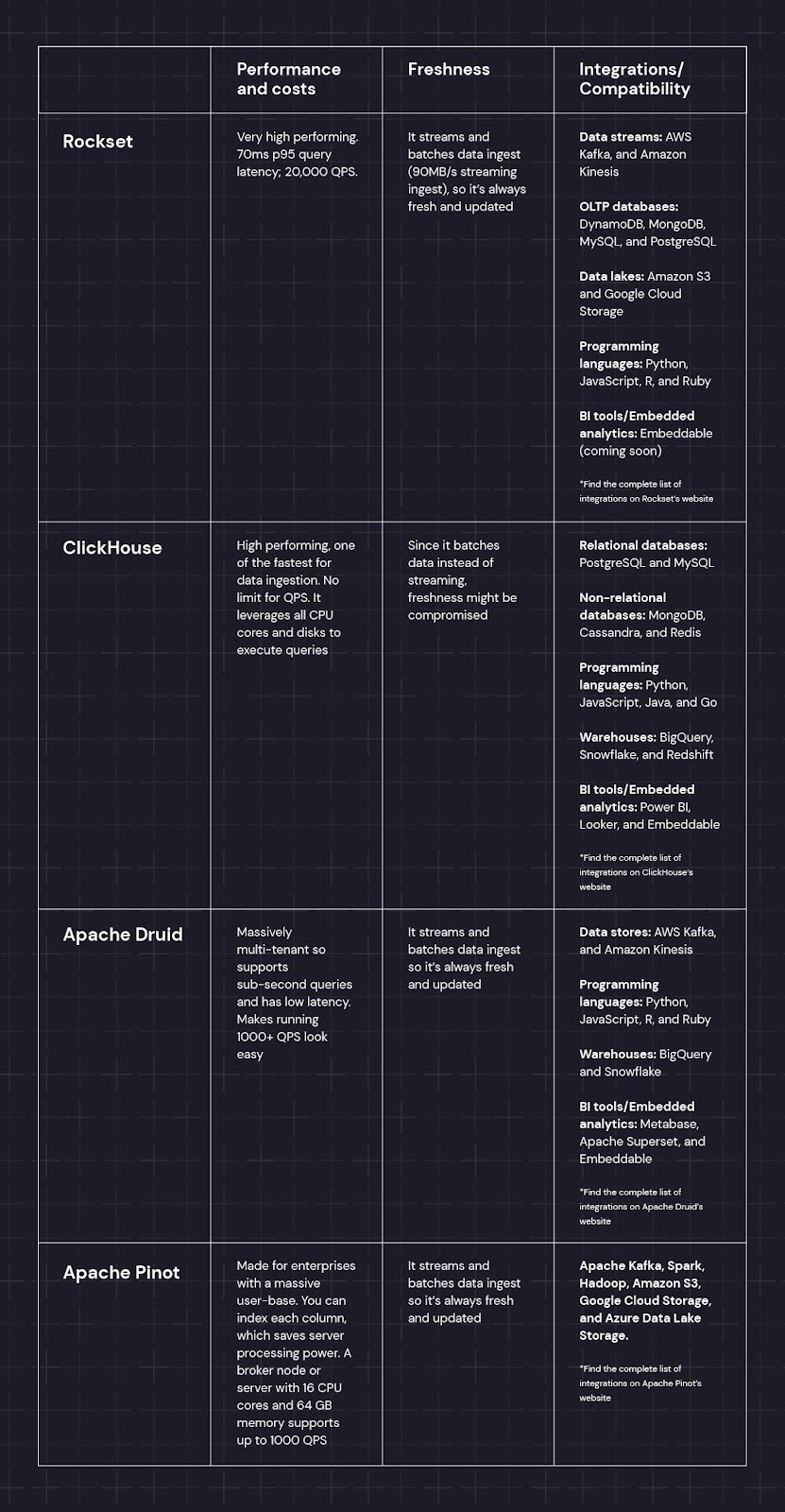
These four database providers will help you create real-time analytics experiences for your end users. However, there are some considerations that you need to take into account. Assuming these are all very fast:
- Use Rockset if you want fast streaming ingestion and need to host your database on the cloud (and you are OpenAI*)
- Use ClickHouse if you want to ingest data in batches and are okay with a minor delay in freshness.
- Use Apache Druid or Pinot if you have a massive user base and your developers have the time to set up and manage the database.
If you’re planning to use Embeddable for building custom user-facing analytics and haven’t yet decided which database is best for your needs, we’re always happy to chat and give some advice if you want it.
With Embeddable, you can build fully bespoke analytics using your own designs in just 10% of the time it would take you to build it from scratch. You control the front-end code, we handle the back-end, and your non-developer team can use our no-code builder to make adjustments in seconds.
Explore how Embeddable can help you deliver remarkable customer-facing analytics. Find out more
Frequently asked questions about best databases for analytics
What is the best database for customer-facing analytics?
The best database for customer-facing analytics depends on several factors, including the scale of data, the need for real-time insights, the complexity of the queries, and the integration with other tools and systems. These four are among the fastest and most performant ones:
- ClickHouse
- Apache Druid
- Apache Pinot
- StarTree
What to look for in a database for real-time analytics?
You should look for these considerations when choosing a database for real-time analytics:
- Performance: Does it process data efficiently? Is it scalable? Can it perform complex queries with ease?
- Loading time: Can it load real time data?
- Integrations: Does it connect to my tech stack?
What are the implications of using a multi-tenant database architecture?
Whether you opt for a single-tenant or a multi-tenant architecture can affect your ability to deliver a great analytics experience for your data consumers. Make sure to consider whether the tool you use to display the analytics can support a multi-tenant architecture and exactly how it achieves this if it does. Many tools use complicated workarounds to support multi-tenant database architectures.
References
- Google Cloud — Google BigQuery Documentation: https://cloud.google.com/bigquery/docs/introduction
- ClickHouse — ClickHouse Documentation: https://clickhouse.com/docs/en/
- Snowflake — Built for scalable BI workloads and data warehousing: https://docs.snowflake.com/en/user-guide/intro-key-concepts
- Apache Druid — Official: sub-second queries at scale: https://druid.apache.org/
- Apache Pinot — Documentation: https://docs.pinot.apache.org/
- Embeddable — What headless BI is and how it could benefit your business here: https://embeddable.com/blog/headless-architectures-in-modern-software-development
- ClickHouse — ClickHouse Homepage: https://clickhouse.com/
- Rockset — Rockset Homepage: https://rockset.com/